728x90
반응형
Document
- document는 텍스트 또는 구조화된 데이터 등의 정보를 저장하는 단위이다.
- Opensearch에서 문서는 JSON 형식으로 저장된다.
Index
- Index는 document의 모음이다.
- Index는 여러가지 방법으로 생각할 수 있다.
- 학생 데이터베이스에서 인덱스는 데이터베이스의 모든 학생을 나타냄.
- 정보를 검색할 때는 인덱스에 포함된 데이터를 쿼리함.
- 인덱스는 기존 데이터베이스의 데이터베이스 테이블을 나타냄.
Cluster와 Node
- Opensearch는 분산 검색 엔진으로 설계되었으며, 하나 이상의 노드에서 실행될 수 있음.
- 즉, 데이터를 저장하고 검색 요청을 처리하는 서버이다.
Shards
- Opensearch는 Index를 Shard로 분할함.
- 각 샤드는 다음 이미지에서 볼 수 있듯이 인덱스에 있는 모든 문서의 하위 집합을 저장함.
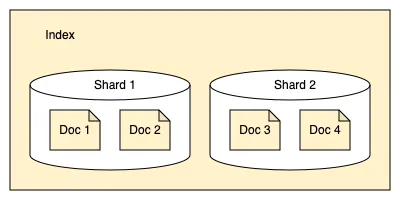
- 샤드는 클러스터의 노드에 균등하게 분배되는데 사용됨.
- 예를 들어, 400G 인덱스는 클러스터의 단일 노드가 처리하기에는 너무 클 수 있지만, 각각 40GB의 샤드 10개로 분할하면 Opensearch는 샤드를 10개 노드에 분배하고 각 샤드를 개별적으로 관리할 수 있음.
- 인덱스 1은 2개 샤드로 분할되고 인덱스2는 4개 샤드로 분할된다. 샤드는 아래 사진처럼 노드 1과 2에 분산됨.

Primary and replica shards
- Primary shard (기본 샤드)와 replica shard가 존재.
- 인덱스를 10개의 샤드로 분할하면 Opensearch는 복제본 샤드를 10개 만듦.
- 위 클러스터에서 각 샤드에 대해 Replica를 1개 추가하면 아래와 같이 인덱스 1에 대한 샤드 2개와 Replica 2개, 인덱스 2에 대한 샤드 4개와 Replica 4개가 포함된다.
- OpenSearch는 Replica shard를 해당 기본 샤드와 다른 노드에 분산하지만 클러스터가 검색 요청을 처리하는 속도도 향상시킨다.

Opensearch REST API
# Cluster Health 확인 API
curl -X GET "http://localhost:9200/_cluster/health"
# Opensearch는 기본적으로 flat JSON 형식으로 응답을 반환한다.
# 사람이 읽을 수 있는 응답 본문의 경우 pretty 쿼리 매개변수를 제공
curl -X GET "http://localhost:9200/_cluster/health?pretty"
# Opensearch Dashboard > 관리 > Dev Tools에서는 더 간단한 구문 사용
GET _cluster/health
# Document 인덱싱: Opensearch 인덱스에 JSON 문서 추가
PUT https://<host>:<port>/<index-name>/_doc/<document-id>
# 예시
PUT /students/_doc/1
{
"name": "John Doe",
"gpa": 3.89,
"grad_year": 2022
}
# Dynamic mapping
# 문서 인덱싱할 때 Opensearch는 문서에 제출된 JSON 유형에서 필드 유형을 유추
GET /students/_mapping
# 응답
{
"students": {
"mappings": {
"properties": {
"gpa": {
"type": "float"
},
"grad_year": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
대량 인덱싱
- 대량으로 문서를 인덱싱하려면 Bulk API를 사용할 수 있음.
# 예시
POST _bulk
{ "create": { "_index": "students", "_id": "2" } }
{ "name": "Jonathan Powers", "gpa": 3.85, "grad_year": 2025 }
{ "create": { "_index": "students", "_id": "3" } }
{ "name": "Jane Doe", "gpa": 3.52, "grad_year": 2024 }
Document 업데이트
- Opensearch에서는 문서를 변경할 수 없음.
- 그러나 문서를 검색하고, 정보를 업데이트하고, 다시 인덱싱하여 문서를 업데이트할 수 있음.
- Index Document API를 사용하여 전체 문서를 업데이트하여 문서의 모든 기존 및 추가된 필드에 대한 값을 제공할 수 있음.
# 문서 전체 업데이트
PUT /students/_doc/1
{
"name": "John Doe",
"gpa": 3.91,
"grad_year": 2022,
"address": "123 Main St."
}
# 문서 일부 업데이트
POST /students/_update/1/
{
"doc": {
"gpa": 3.91,
"address": "123 Main St."
}
}Document & Index 삭제
# 문서 삭제
DELETE /students/_doc/1
# 인덱스 삭제
DELETE /students
Document 검색
GET /students/_search
{
"query": {
"match": {
"name": "john"
# "match_all": {} # 조건 설정 안할 경우
}
}
}
Response fields
- took : 쿼리를 실행하는데 걸린 시간(밀리초)
- timed_out : 시간 초과 여부. 설정한 시간보다 초과되면 시간 초과 전까지 수집된 결과를 반환함.
GET /students/_search?timeout=20ms- _shards : 쿼리가 실행된 샤드의 총 수와 성공 또는 실패한 샤드의 수를 지정
- 관련 샤드 중 하나가 실패하면 나머지 샤드에서 계속 실행
- hits : 일치하는 문서의 총 수와 문서 자체. 각 일치하는 문서에는 _id와 _source 필드가 포함되고, _index 필드에는 원래 인덱싱된 전체 문서가 포함됨.
문자열 쿼리
GET /students/_search?q=name:john
# 조건과 일치하는 문서 반환
{
"took": 18,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 0.9808291,
"_source": {
"name": "John Doe",
"grade": 12,
"gpa": 3.89,
"grad_year": 2022,
"future_plans": "John plans to be a computer science major"
}
}
]
}
}
DSL 쿼리
- 더 복잡하고 사용자 지정된 쿼리를 만들기 위해 사용
- 쿼리 시 소문자 john을 전달해도 대문자 John을 포함할 수 있음.
GET /students/_search
{
"query": {
"match": {
"name": "john"
}
}
}
- 검색 문자열에서 용어를 재정렬할 수도 있음.
- doe john을 검색했지만, John Doe과 Jane Doe를 반환
- 일치 쿼리 유형은 기본적으로 OR 연산자를 사용함. 즉, doe OR john
GET /students/_search
{
"query": {
"match": {
"name": "doe john"
}
}
}
# 응답 결과
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.4508327,
"hits": [
{
"_index": "students",
"_id": "1",
"_score": 1.4508327,
"_source": {
"name": "John Doe",
"gpa": 3.89,
"grad_year": 2022
}
},
{
"_index": "students",
"_id": "3",
"_score": 0.4700036,
"_source": {
"name": "Jane Doe",
"gpa": 3.52,
"grad_year": 2024
}
}
]
}
}Relevance score
- relevance score는 document가 쿼리와 얼마나 잘 일치하는지 측정함.
- 이는 Opensearch가 각 문서의 메타데이터 _score 필드에 기록하는 양의 부동소수점 숫자이다.
- 다른 쿼리 유형은 Relevance score를 다르게 계산하지만 모든 쿼리 유형은 쿼리 절이 필터 또는 쿼리 컨텍스트에서 실행되는지 여부를 고려함.
- Relevance score에 영향을 주고 싶은 쿼리 절은 쿼리 컨텍스트에서 사용하고, 다른 모든 쿼리 절은 필터 컨텍스트에서 사용함.
"hits" : [
{
"_index" : "shakespeare",
"_id" : "32437",
"_score" : 18.781435,
"_source" : {
"type" : "line",
"line_id" : 32438,
"play_name" : "Hamlet",
"speech_number" : 3,
"line_number" : "1.1.3",
"speaker" : "BERNARDO",
"text_entry" : "Long live the king!"
}
},
...1) 필터 컨텍스트
- 필터 컨텍스트를 사용하면 “정확히 일치하는지?” 질문을 함.
- 필터 컨텍스트를 사용하면 Opensearch는 관련성 점수를 계산하지 않고 일치하는 문서를 반환함. 따라서 정확한 값이 있는 필드에는 필터 컨텍스트를 사용해야함.
- 필터 컨텍스트에서 쿼리 절을 실행하려면 filter 매개변수에 전달함.
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "honors": true }},
{ "range": { "graduation_year": { "gte": 2020, "lte": 2022 }}}
]
}
}
}
2) 쿼리 컨텍스트
- 쿼리 컨텍스트를 사용하면 “얼마나 잘 일치하는지?” 질문을 함.
- 쿼리 컨텍스트는 전체 텍스트 검색에 적합하며, 여기서는 일치하는 문서를 받을뿐만 아니라 각 문서의 관련성도 확인해야함.
- 쿼리 컨텍스트를 사용하면 일치하는 모든 문서의 _score 필드에 Relevance score가 포함됨.
- 쿼리 컨텍스트에서 쿼리 절을 실행하려면 query 매개변수에 전달함.
GET shakespeare/_search
{
"query": {
"match": {
"text_entry": "long live king"
}
}
}
키워드 검색
- name 필드에는 자동으로 추가되는 name.keyword 필드가 포함되어 있음.
- 아래와 같이 검색하면 keyword 필드가 정확히 일치해야만 결과를 반환함.
GET /students/_search
{
"query": {
"match": {
"name.keyword": "john"
}
}
}
# 아무런 결과도 반환하지 않음.Filter
- 부울 쿼리를 사용하면 정확한 값이 있는 필드에 대한 필터 절을 쿼리에 추가할 수 있음.
- 예를 들어 졸업 연도가 2022년인 학생을 검색하는 쿼리는 다음과 같다.
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "grad_year": 2022 }}
]
}
}
}- 범위 필터를 지정하는 것도 가능하다. 다음 부울 쿼리는 GPA가 3.6보다 큰 학생을 검색한다.
GET students/_search
{
"query": {
"bool": {
"filter": [
{ "range": { "gpa": { "gt": 3.6 }}}
]
}
}
}
복합 쿼리
- 복합 쿼리를 사용하면 여러 쿼리 또는 필터 절을 결합할 수 있다.
- 예를 들어, doe와 이름이 일치하는 학생을 검색하고 졸업 연도와 GPA로 필터링하려면 아래 요청을 사용한다.
GET students/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "doe"
}
},
{ "range": { "gpa": { "gte": 3.6, "lte": 3.9 } } },
{ "term": { "grad_year": 2022 }}
]
}
}
}
집계 함수
평균 집계
- taxful_total_price 필드의 평균을 계산한다.
GET opensearch_dashboards_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"avg_taxful_total_price": {
"avg": {
"field": "taxful_total_price"
}
}
}
}
# 응답 결과
{
"took": 85,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4675,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"avg_taxful_total_price": {
"value": 75.05542864304813
}
}
}
Cardinality Aggregation
- cardinality는 필드의 고유값 또는 고유 값의 수를 세는 단일값 메트릭 집계이다.
- 아래는 전자상거래 매장의 고유한 제품 수를 찾는 것.
GET opensearch_dashboards_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"unique_products": {
"cardinality": {
"field": "products.product_id"
}
}
}
}
# 응답 결과
...
"aggregations" : {
"unique_products" : {
"value" : 7033
}
}
}- precision_threshold 설정으로 메모리와 정확도 간의 균형을 제어할 수 있음.
- 이는 count가 정확도에 가까워질 것으로 예상되는 임계값을 정의. 기본값은 3000이고, 최댓값은 40000이다.
GET opensearch_dashboards_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"unique_products": {
"cardinality": {
"field": "products.product_id",
"precision_threshold": 10000
}
}
}
}- extended_stats 는 확장 버전으로 std_deviation_bounds 객체는 평균에서 +/- 2표준편차의 간격으로 데이터의 시각적 분산을 제공함.
GET opensearch_dashboards_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"extended_stats_taxful_total_price": {
"extended_stats": {
"field": "taxful_total_price",
"sigma": 3
}
}
}
}백분위수 집계
- 백분위수는 특정 임계값에 도달하거나 그보다 낮은 값에 있는 데이터의 백분율이다.
- percentile은 데이터에서 이상치를 찾거나 데이터 분포를 파악하는데 도움이 됨.
GET opensearch_dashboards_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"extended_stats_taxful_total_price": {
"extended_stats": {
"field": "taxful_total_price",
"sigma": 3
}
}
}
}
//응답
...
"aggregations" : {
"percentile_taxful_total_price" : {
"values" : {
"1.0" : 21.984375,
"5.0" : 27.984375,
"25.0" : 44.96875,
"50.0" : 64.22061688311689,
"75.0" : 93.0,
"95.0" : 156.0,
"99.0" : 222.0
}
}
}
}
참고
https://opensearch.org/docs/latest/getting-started/intro/
728x90
반응형
'Database > Opensearch' 카테고리의 다른 글
| Opensearch 유사도 검색 (1) | 2024.11.21 |
|---|---|
| Opensearch Tokenizer, Analyzer와 Custom Analyzer 적용 (3) | 2024.11.20 |
| Opensearch Ingest pipeline으로 로그파일 전처리 (0) | 2024.11.19 |