1. Cassandra란
- 이름의 유래는 그리스 로마신화 카산드라. (예언의 능력이 있지만 아무도 믿지 않았던) 그래서 로고도 반짝이는 눈 모양으로 추정.
- 대용량 데이터를 관리하기 위해 설계된 고성능 분산 NoSQL 데이터베이스
- Google의 Big Table과 Amazon의 Dynamo를 섞어서 만든 key-value 및 Column 형태의 종합적인 플랫폼이라고 할 수 있다.

- 노드는 카산드라의 인스턴스로 구성되고, 여러 노드들은 Gossip이라고 불리는 프로토콜을 통해 소통한다.
- 카산드라는 master가 없는 Ring 구조로 구성되어 모든 노드가 같은 역할과 기능을 수행한다. (P2P를 지원)
- 카산드라는 SQL과 비슷한 Cassandra Query Language(CQL)를 이용
장점
- 분산화: 카산드라는 DB를 분산하여 여러 인스턴스에서 구동할 수 있다. 분산화되어있는 여러 DB를 하나의 DB처럼 조작 가능.
- 기존 다른 DB처럼 Primary-Replica 형식이 아닌, 각 노드가 모두 Primary에 해당
- 각 노드들은 P2P 프로토콜을 통한 동기화 작업 수행
- SPOF(single point of failure) 발생 위험이 없음
- 확장성: 노드를 추가하면 성능 처리량이 linear하게 증가. 전체 클러스터 재구성 없이도 노드 수 증가/감소 용이. 동기화 및 위치에 따라서 고민하지 않아도 됨.
- 고가용성과 결함 허용: 한 개의 노드에 장애 발생 시 클러스터에서 탐지 및 교체. 복원 기능을 가지고 있다.
단점
- 높은 진입 장벽: Column 형 DB이기 때문에 기존의 Row형 RDB와는 달라 진입 장벽이 높다.
- 복잡한 쿼리는 불가능: 대량의 데이터에 적합하나, 검색 조건은 단순한 서비스에 국한된다.
- 데이터 입력 시 자동화 처리가 어려움: 데이터에 대한 Lock을 사용하려면 Zookeeper 등 분산 서버 관리 프로그램을 통해 별도로 설정해줘야한다
Cassandra와 MongoDB 비교
- MongoDB와 Cassandra는 모두 NoSQL 데이터베이스이지만 데이터를 저장하고 관리하는 방식이 서로 다르다.
- CAP 및 PACELC 이론을 근거로 MongoDB는 가용성보다는 일관성을 보장하는 분산 시스템이고 Cassandra는 가용성을 추구하는 시스템으로 분류 (맨 아래 CAP 이론 참고)
2. Cassandra 구조 및 접근 방법
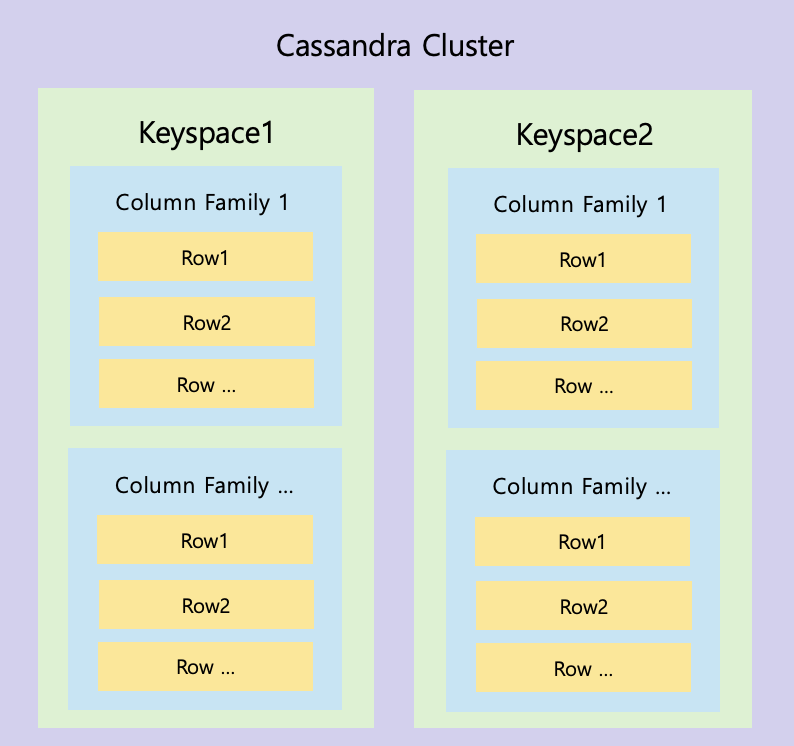
2.1 Cassandra 구성요소
- keyspace: 논리적 데이터 저장소, DB와 유사한 개념
- table: 데이터 스키마
- partition: 모든 행에 있어야 하는 기본 키의 필수 부분 정의
- row: 파티션 키 및 추가 클러스터링 키, 구성된 고유한 기본키로 식별되는 열 모음
- column: 해당 테이블에서 행에 속하는 열
2.2 Cassandra Coordinator
- 카산드라는 Master 역할을 하는 노드가 존재하지 않는다고 했지만, 클라이언트가 카산드라에 접근하기 위해선 접속할 특정 노드를 지정해야한다.
- 아래 그림은 예시로 클라이언트가 7번 노드로 접근했다고 가정한다. 이때 1번 노드를 Coordinator라고 한다.

Cassandra Data Read
- coordinator는 클라이언트가 요청한 데이터가 클러스터의 어느 노드에 있는지 확인 후 해당 노드에 데이터를 요청한다.
- coordinator는 해당 노드로부터 전달받은 데이터를 클라이언트로 전달한다.
Cassandra Data Write
- coordinator는 클라이언트가 저장하려는 데이터가 클러스터의 어느 노드에 저장되어야 하는지 확인
- 해당 노드는 전달받은 데이터를 저장한다.
- 그리고 데이터를 RF(Replication factor)의 수만큼 주변의 노드에 복제한다.
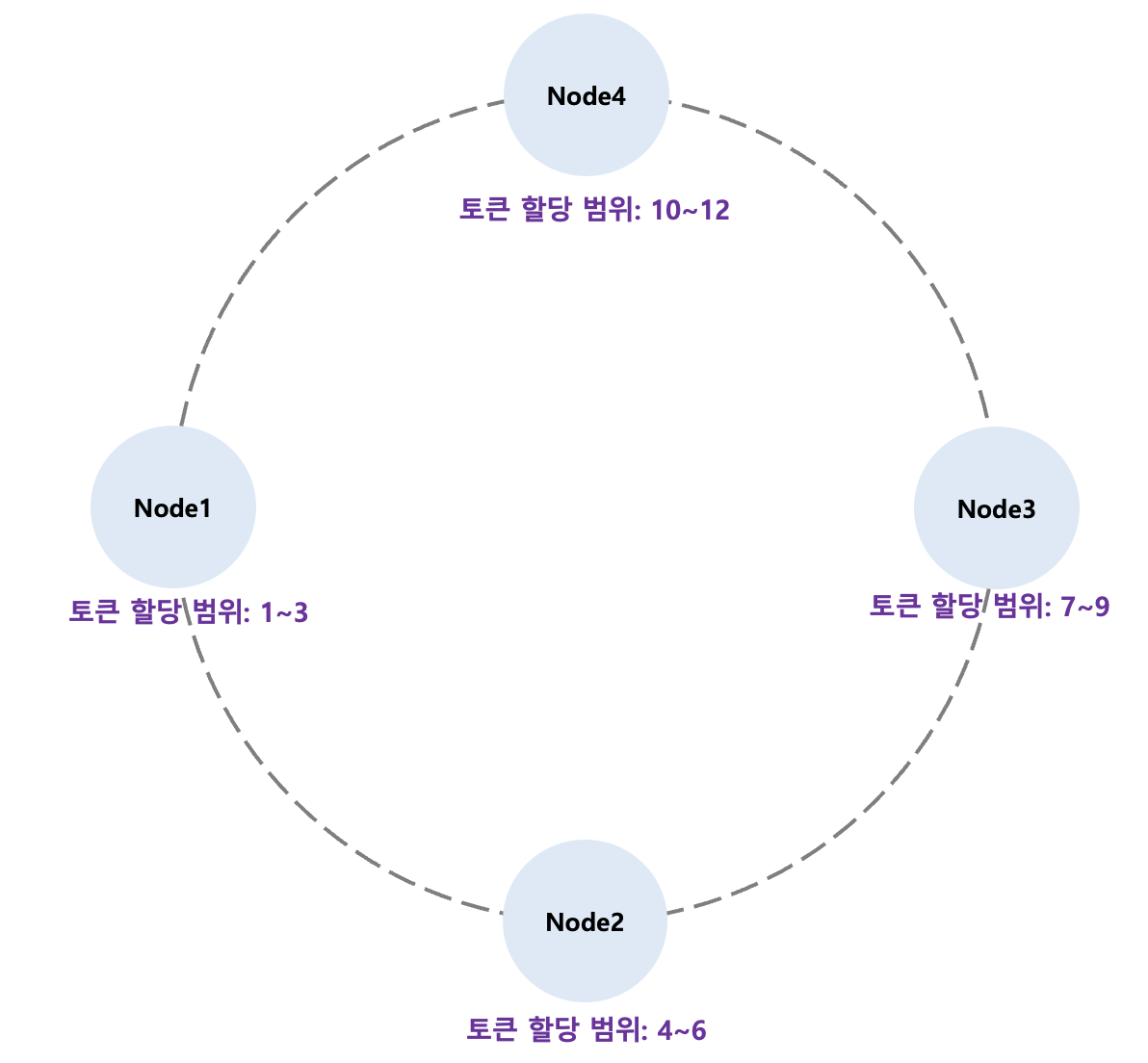
2.3 Cassandra의 파티션
- 파티션을 통해 데이터 자동 분산.
- 각 노드가 특정 토큰의 set을 가지고 있고, Cassandra가 이런 토큰의 범위를 기반으로 해서 데이터를 나눈다.
- 아래 그림을 보면, 원본 데이터에 Partition key가 될 항목은 "Country"로 지정했고, 이 값을 Partitioner (Hashing Function)에 넣어서 카산드라 노드 들이 갖고 있는 Token 범위로 해싱한 뒤, 해싱 결과에 따라 맞는 노드에 저장한다.

- 데이터가 들어오면, 카산드라의 조정자(coordinator)가 데이터를 특정 파티션에 할당.
- 그리고 실제로 저장할 때는 이 파티션이 어떤 토큰 범위에 해당하는지 다른 노드와 소통하기 위해 Gossip이라는 프로토콜 사용
- 카산드라는 RF(Replication factor)라는 개념을 지원하는데, RF는 얼마나 많은 복사본이 존재해야만 하는지를 나타낸다.
- 하나의 데이터를 여러 노드에 복사함으로써 신뢰성을 높이고 장애를 방지한다.
2.4 Virtual Node(vnode)
- 카산드라의 초기 버전(ver. 1.1 이하)에서는 위 이미지처럼 노드마다 오직 하나의 토큰 범위를 수작업으로 할당했다.
- 그러므로 노드가 추가되거나 제거되면 기존의 토큰 범위 조정이 필요했다. 즉, 데이터의 이동도 발생
- 이러한 문제를 개선하기 위해 카산드라 ver. 1.2부터 Virtual Node(vnode)라는 개념을 도입하여 노드마다 연속적이지 않는 여러 개의 토큰 범위를 가질 수 있게 되었다.

2.5 키스페이스 (Keyspace)
- 카산드라에서는 테이블을 생성하기 전에 반드시 키스페이스(Keyspace)를 생성해야 한다.
- 키스페이스 생성 시 데이터를 몇 개의 노드에 복제할지 RF(Replication Factor)를 선언해준다.
- 예를 들어, RF를 3으로 선언한 경우는 저장된 데이터를 인접한 두개의 노드에 데이터를 복제한다.
- 만약 RF를 테이블마다 다르게 적용해야한다면, RF의 종류만큼 키스페이스를 만들어야한다.
- 동일한 키스페이스에는 RF를 하나만 지정할 수 있기 때문
- 다음은 키스페이스를 생성하는 CQL(Cassandra Query Language) 문장 구조이다.
- SimpleStrategy: 테스트 환경 또는 단일 데이터센터용 복제 전략
- NetworkTopologyStrategy: 다중 데이터센터에 최적화된 전략
- replication_factor: 데이터 복제본
- dc1, dc2: 데이터센터 이름 및 각 데이터센터에 저장할 복제본 수
- durable_writes: true로 설정 시, commit log에 먼저 기록 후 반영 (기본값은 true)
CREATE KEYSPACE [IF NOT EXISTS] keyspace_name
WITH REPLICATION={replication_map}
[AND DURABLE_WRITES = true|false];
-- Keyspace 생성 예시
CREATE KEYSPACE my_keyspace
WITH replication = {
'class': 'SimpleStrategy',
'replication_factor': 1
};
AND durable_writes = true;
CREATE KEYSPACE prod_keyspace
WITH replication = {
'class': 'NetworkTopologyStrategy',
'dc1': 3,
'dc2': 2
};
2.6 클러스터링 키(Clustering key)
- 클러스터링 키는 데이터가 배치된 노드 내에서 디스크의 어떤 위치에 저장될지를 결정한다. (어느 노드에 저장될지는 관여하지 않음!!)
- 노드 내 모든 데이터는 클러스터링 키를 기준으로 정렬되어 저장된다.
- 아래 카산드라 테이블 생성하는 CQL에서 PRIMARY KEY 부문을 보면,
- 기본키의 첫번째 key인 (month, day)는 파티션 키(Partition Key), 나머지 키 station_id, time은 클러스터링 키(Clustering Key)가 된다.
CREATE TABLE weather_data_by_data(
month BIGINT,
day BIGINT,
station_id UUID,
time timestamp,
temperature DOUBLE,
wind_speed DOUBLE,
PRIMARY KEY((month, day), station_id, time)) -- station_id, time:
WITH CLUSTERING ORDER BY (station_id DESC, time ASC);
3. CAP 이론
3.1 개요
- CAP는 분산 데이터베이스 속성에 관한 이론으로써, 성능과 안정성 간의 tradeoff를 설명하는 이론이다.
- 분산 데이터베이스는 수평 확장이 가능하고 장애 대응에 유리하여 대규모 데이터 처리에 적합하다.
- NoSQL 데이터베이스는 대표적인 분산 데이터베이스이며, 유연하게 데이터를 다룰 수 있다는 장점이 있다.
- NoSQL 데이터베이스는 서로 다른 특징을 가진 여러 제품이 있기 때문에 애플리케이션에 맞는 특성에 맞는 데이터베이스를 선택해야 한다. 이를 위해서는 각 제품 의 특징뿐만 아니라 데이터베이스 이론 또한 이해해야 한다.

3.2 Consistency (일관성)
- 일관성은 사용자가 분산 데이터베이스 상의 어떤 노드와 통신하는 지 상관없이 같은 데이터를 조회할 수 있는 것을 의미한다.
- 즉, 한 노드에서 데이터가 변경되면 모든 복제본에 즉시 반영되어야 하며, 어느 클라이언트든 같은 값을 조회할 수 있어야 한다.
- 완벽한 즉시 반영은 어렵지만, 사용자에게 문제가 없을 정도의 빠른 동기화가 일관성의 목표이다.
- 일관성은 금융이나 개인정보와 같이 모든 사용자가 일관성있는 데이터를 조회해야할 때 중요하다. 예를들어 금융 앱을 이용할 때 PC나 스마트폰, 태블릿 또는 어디 에서 보든 지 같은 잔고를 확인할 수 있어야 한다.
4.3 Availability (가용성)
- 가용성이란 모든 요청이 응답을 받을 수 있어야 한다는 것을 의미한다.
- 읽기든 쓰기든 모든 요청에 응답이 있어야 하며, 일관성이 다소 깨지더라도 시스템이 중단 없이 동작해야 한다.
- 예를들어 스마트폰과 PC에서 은행앱을 사용할 때 서로 잔고가 일치하지 않더라도 잔고를 조회할 수 있어야 한다.
4.4 Partition Tolerance (분할 허용)
- 분할이란, 노드 간 통신이 끊어지는 것을 의미
- 분할 허용은 네트워크 장애로 노드 간 통신이 끊겨도 시스템이 계속 동작하는 것을 의미한다.
- 이를 위해 데이터 복제본을 여러 노드에 저장하며, 통신이 단절된 상황에서도 다른 노드가 요청에 응답할 수 있어야 한다.
- 분할 허용성은 분산 데이터베이스 시스템에서 필수적인 요소이다.
4.5 CAP 이론이란?
- CAP 이론은 분산 시스템에서 분할이 발생하면 일관성(C)과 가용성(A) 중 하나를 포기해야 한다는 이론이다.
- 분산 시스템은 분할 허용성(P)이 필수이므로, 결국 CP(일관성 + 분할 허용) 또는 AP(가용성 + 분할 허용) 중 하나를 선택해야 한다.
- 예를 들어 두 노드로 이루어진 분산 시스템에서 분할이 생겼을 때 데이터의 일관성을 보장하기란 불가능하다. 그러므로 분할이 생겼더라도 정상적으로 요청을 처 리해 일관성을 희생하고 가용성을 높이던지, 잠시 요청 처리를 중단하고 중단된 노드가 재실행될 때까지 기다려 가용성을 희생하고 일관성을 지키는 방법 중 하나 를 선택해야 한다.
⇒ 따라서 NoSQL 데이터베이스는 CP 시스템과 AP 시스템으로 분류
⇒ CA 시스템은 일반적으로 하나의 노드에서 동작하는 모놀리식 데이터베이스 시스템을 의미.
4.6 Cassandra의 AP
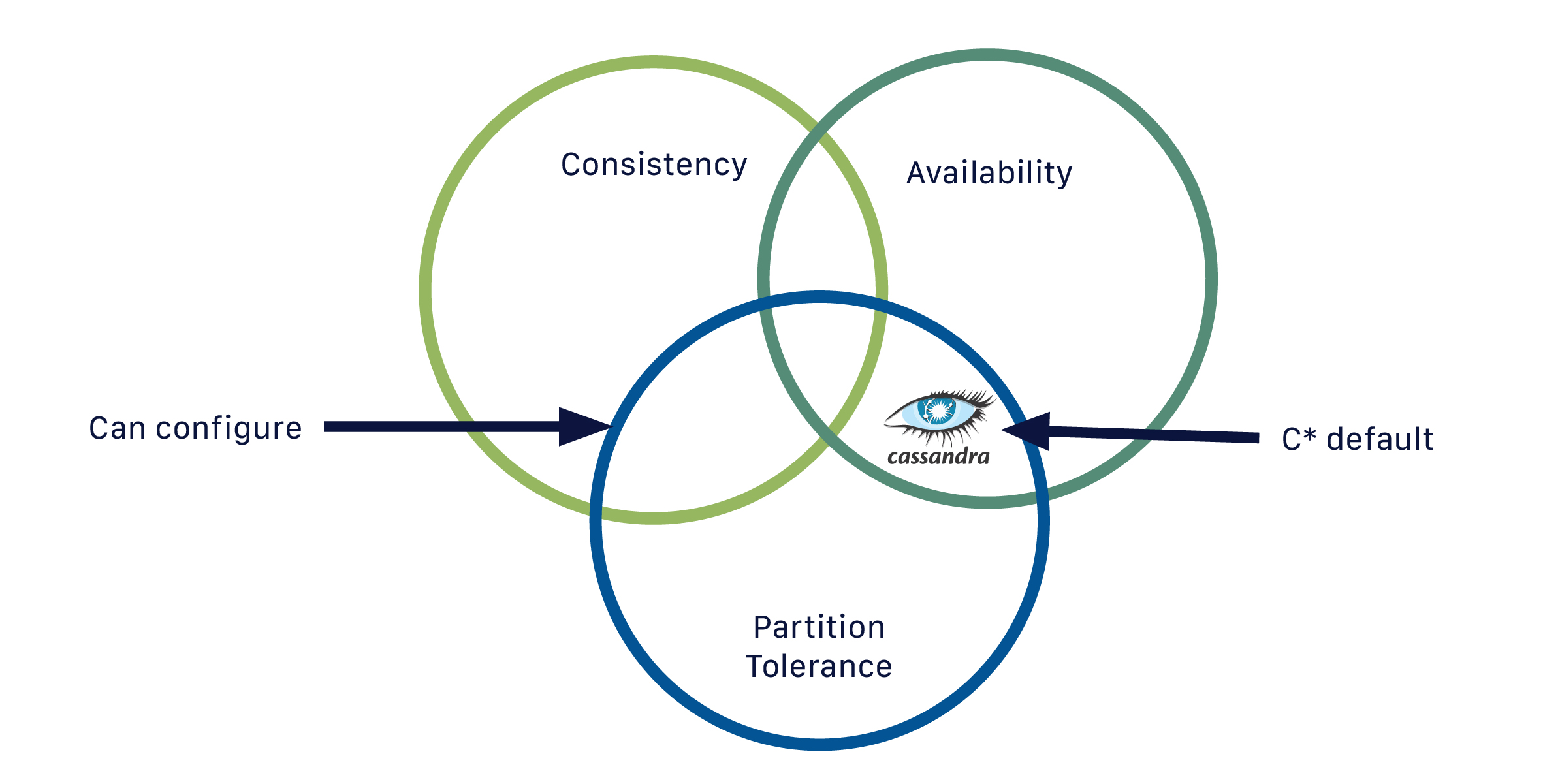
- Cassandra는 일관성을 일부 포기하고 가용성을 우선시하는 AP 시스템으로 분류된다.
- 즉, 카산드라는 primary node 없이 모든 노드가 읽기 작업과 쓰기 작업을 수행할 수 있고 복제본을 분리된 다른 노드에 저장한다.
- 카산드라는 지정된 복제 계수(RF)만큼 데이터를 시계 방향으로 인접한 노드에 복제한다.
- 한 노드가 노드 간 통신에서 끊어진 상황을 가정해보자. 해당 노드가 다른 노드와 통신할 수 없어도 해당 노드는 여전히 읽기 작업과 쓰기 작업을 수행할 수 있으나 데이터가 다른 노드와 맞지 않는 상태, 즉 일관성이 깨진 상태가 된다.
- 카산드라는 이를 최종적 일관성(Eventual Consistency)를 통해 나중에 데이터를 동기화한다. 따라서 모든 노드간 데이터가 동기화되기 전까지 각 노드는 서로 다 른 버전의 데이터를 가지고 있다.
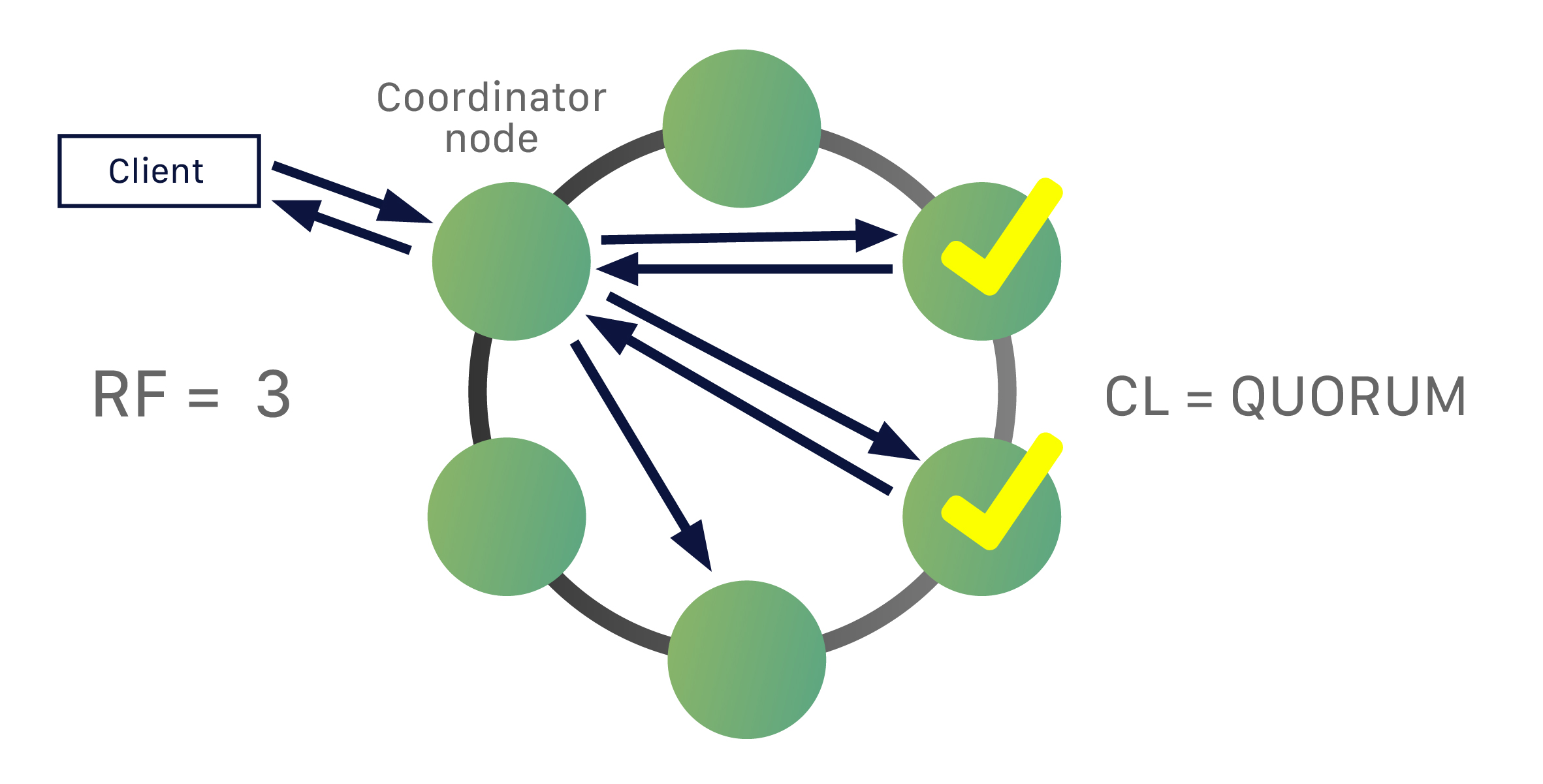
4.7 Consistency level
- consistency level은 작업이 성공으로 간주되기 전에 coordinator에게 Read 또는 Write 작업을 확인 응답해야하는 최소 Cassandra 노드 수를 나타낸다.
- 일반적으로 복제 계수(RF)를 기반으로 일관성 수준(CL)을 선택한다.
- 위 그림에서는 데이터가 3개의 노드로 복제되며 CL=QUORUM (쿼럼은 과반수를 의미하며, 이 경우 복제본 2개 또는 RF/2+1)이므로, coordinator는 쿼리가 성공으로 간주되려면 복제본 2개로부터 확인 응답을 받아야한다.
다음 게시물
https://daeunnniii.tistory.com/214
Cassandra의 스토리지와 Read, Write 동작 원리
0. 이전 게시글https://daeunnniii.tistory.com/213 Cassandra 구조와 원리 (feat. CAP 이론)1. Cassandra란 이름의 유래는 그리스 로마신화 카산드라. (예언의 능력이 있지만 아무도 믿지 않았던) 그래서 로고도 반
daeunnniii.tistory.com
참고
https://cassandra.apache.org/_/cassandra-basics.html
https://clarkshim.tistory.com/168
https://newstellar.tistory.com/30
https://newstellar.tistory.com/40
https://juneyr.dev/quick-cassandra
https://nicewoong.github.io/development/2018/02/11/cassandra-feature/
https://front-kuli.tistory.com/193 https://www.analyticsvidhya.com/blog/2020/08/a-beginners-guide-to-cap-theorem-for-data-engineering/ https://onduway.tistory.com/106 https://velog.io/@dodozee/CAP-이론이란-PACELC-이론이란-feat.-블록체인 https://dongwooklee96.github.io/post/2021/03/26/cap-이론이란/
'Database > Cassandra' 카테고리의 다른 글
| Cassandra의 스토리지와 Read, Write 동작 원리 (1) | 2025.05.01 |
|---|