728x90
반응형
RNN의 문제점
1. Gradient Vanishing

- 긴 sequence에서 역전파를 진행할 때 위와 같이 각 편미분 값이 1보다 작고, hidden layer의 개수가 100개가 넘어가면 결국 $ \frac{\partial E}{\partial W} $ 값이 0에 가까워져서 결국 가중치 업데이트가 거의 이루어지지 않아 학습이 매우 길어지고 비효율적이게 됨.
2. Gradient Exploding

- 마찬가지로 긴 sequence에서 역전파를 진행할 때 위와 같이 각 편미분 값이 1보다 크고, hidden layer의 개수가 100개가 넘어가면 결국 $ \frac{\partial E}{\partial W} $ 값이 커지게 되고 가중치 업데이트가 왔다갔다 변동이 커짐.
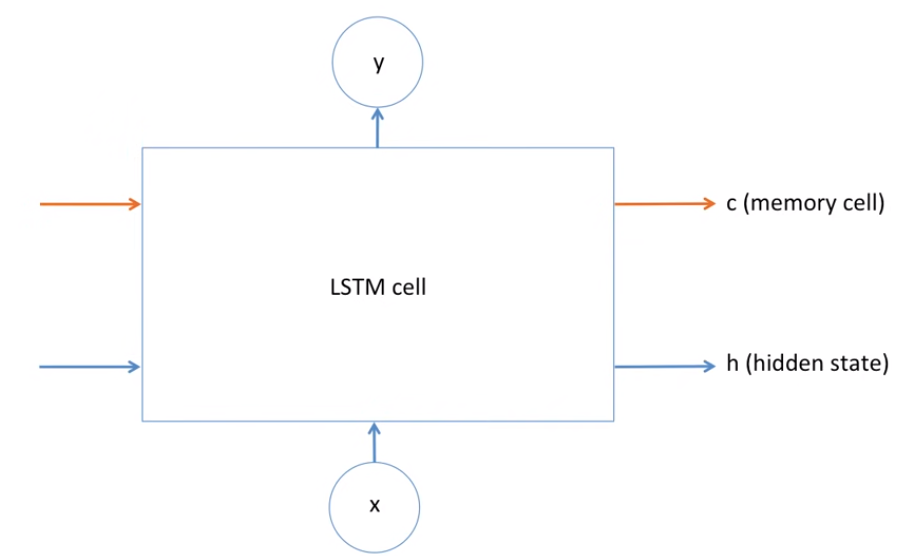
LSTM
- LSTM은 RNN의 특별한 한 종류로, 긴 의존 기간을 필요로 하는 학습을 수행할 능력을 갖고 있음
- sequence가 길 경우 학습이 비효율적이게 되는 위 문제점을 해결하기 위해 LSTM을 사용
- LSTM에는 RNN에 memory cell이 추가됨.
- C (memory cell)에 해당하는 부분이 과거에 대한 기억을 얼마나 반영할 것인지에 대해 관여
LSTM 연산 과정


- 맨 위에 컨베이너 벨트처럼 흐르는 C값이 cell state.
- LSTM은 세 가지 게이트 (forget, input, output gate)를 통해 cell state를 제어하여 vanishing gradient를 방지하고 그래디언트가 효과적으로 흐를 수 있게 함.
- 1) forget gate
- forget gate $ f_t $ 는 말그대로 ‘과거 정보를 잊기’위한 게이트다. 시그모이드 함수의 출력 범위는 0 ~ 1 이기 때문에 그 값이 0이라면 이전 상태의 정보는 잊고, 1이라면 이전 상태의 정보를 온전히 기억하게 된다.

- 2) input gate
-
- input gate $ i_t $는 ‘현재 정보를 기억하기’위한 게이트다. 이 값은 시그모이드 이므로 0 ~ 1 이지만 hadamard product를 하는 $ \tilde{C}_t $는 hyperbolic tangent 결과이므로 -1 ~ 1이 된다. 따라서 결과는 음수가 될 수도 있다.

- 3) cell gate 업데이트
-
- 그 다음은 cell gate 업데이트로, 앞 단계에서 이미 어떤 값을 얼마나 업데이트할지 정해놓았으므로 그 일을 실천하는 단계이다.
- 이 단계에서는 과거 state인 $ C_{t-1} $을 업데이트해서 새로운 cell state인 $ C_t $를 만든다.
- 우선 이전 state에 $ f_t $를 곱해서 얼마나 잊어버릴지 정한 만큼 진짜로 잊어버린다. 그리고 $ i_t * \tilde{C}_t $를 더하여 얼마나 업데이트할지 정한 만큼 업데이트한다.

- 4) output gate
-
- output gate $ o_t $는 최종 결과 $ h_t $를 위한 게이트이다.
- 우선 sigmoid layer에 input 데이터를 태워서 cell state의 어느 부분을 output으로 내보낼 지를 정한다.
- 그리고 cell state를 tanh layer에 태워서 -1과 1 사이의 값을 받은 뒤에 계산한 sigmoid gate의 output과 곱해준다.
- 그렇게 하면 우리가 output으로 보내고자 하는 부분만 내보낼 수 있게 된다.

- $ x_t $와 $ h_{t−1} $에 서로 다른 가중치를 부여하며, $ \tilde{C}_t $는 따로 지정하지 않고 $ c_t $ 수식에 inline 형태로 삽입함.
Pytorch를 활용한 LSTM 구현
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
import torch.optim as optim
import matplotlib.pyplot as plt
from tqdm import trange
# 데이터 로드
'''
생략
'''
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, sequence_length, num_layers, device):
super(LSTM, self).__init__()
self.device = device
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size*sequence_length, 1)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device)
c0 = torch.zeros(self.num_layers, x.size()[0], self.hidden_size).to(self.device) # <- cell state 추가
out, _ = self.lstm(x, (h0, c0)) # output, (hn, cn): cell state와 hidden state만 반환
out = out.reshape(out.shape[0], -1) # <- state 추가
out = self.fc(out)
return out
model = LSTM(input_size=input_size,
hidden_size=hidden_size,
sequence_length=sequence_length,
num_layers=num_layers, device=device)
model = model.to(device)
criterion = nn.MSELoss()
lr = 1e-3
num_epochs = 100
optimizer = optim.Adam(model.parameters(), lr=lr)
# 모델 학습
loss_graph = []
n = len(train_loader)
pbar = trange(num_epochs)
for epoch in pbar:
running_loss = 0.0
for data in train_loader:
seq, target = data # 배치 데이터
out = model(seq)
loss = criterion(out, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
l = running_loss/n
loss_graph.append(l)
pbar.set_postfix({'epoch': epoch+1, 'loss' : l})
# loss 확인
plt.figure(figsize=(16,8))
plt.plot(loss_graph)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
LSTM & GRU 비교
| LSTM | GRU |
| Control the exposure of memory content (cell state) | Expose the entire cell state to other units in the network |
| gate 수 3개(forget, input, output) | gate 수 2개(reset, update) |
| Has separate input and forget gates | Performs both of these operations together via update gate |
| More parameters | Fewer parameters |

728x90
반응형
'AI > 딥러닝' 카테고리의 다른 글
| Residual Attention Network for Image Classification (2017) 논문 분석 (1) | 2024.03.17 |
|---|---|
| GRU(Gated Recurrent Unit) 정리 (1) | 2024.03.17 |
| RNN(Recurrent Neural Network) 정리 (0) | 2024.03.17 |
| MLP(Multi-Layer Perceptron)과 CNN(Convolutional Neural Network) 정리 (0) | 2024.03.17 |
| [Pytorch] 데이터 로드하기 - Dataset, DataLoader 정리 (0) | 2023.03.28 |