728x90
반응형
1. Introduction
위 논문은 CNN에 Attention을 적용한 논문으로, ResNet에 Attention mechanism을 사용했다.
- Residual Attention Network는 Attention Module로 이루어져있고, Attention 모듈 내부에는 크게 마스크를 생성하는 부분과, 기존 모듈(residual 모듈, inception 모듈) 두 파트로 이루어져 있다.
- 기존 모듈의 출력값에 마스크를 곱하여 출력값의 픽셀에 가중치를 부여하는 것. 즉, Attention module은 이미지에서 중요한 특징을 포착하여 출력값을 정제해주는 역할을 한다.
- Attention module이 깊게 쌓일 수록 다양한 특징을 포착하고 가중치를 부여할 수 있어 성능이 향상된다.
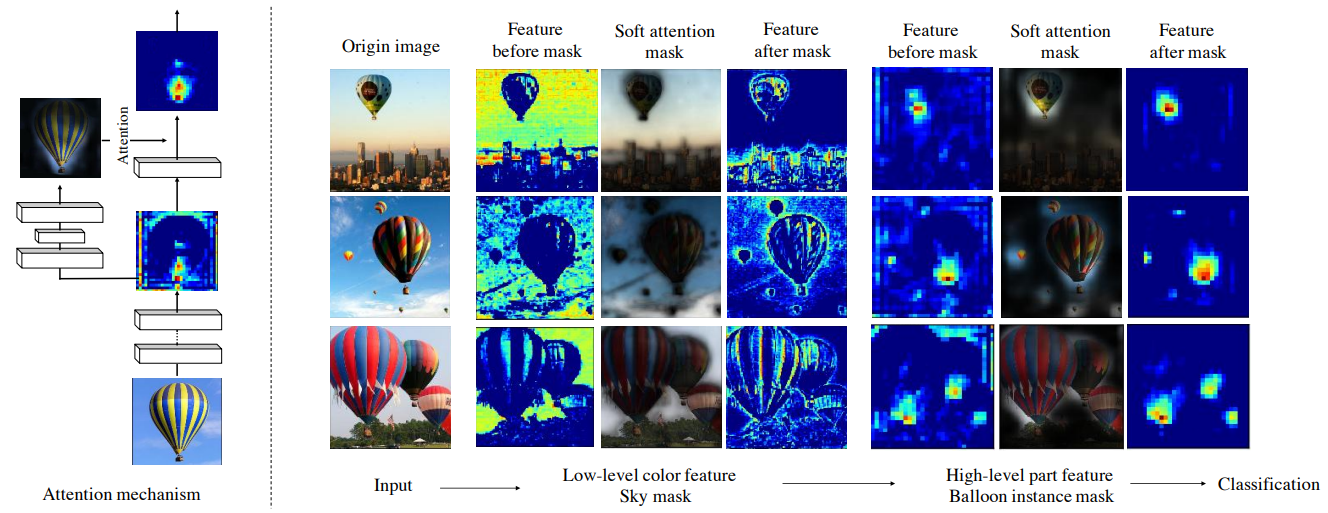
- 위 그림을 보면 기존 이미지에서 생성한 피처맵이 Soft attention mask와 곱해져 중요하지 않은 정보라고 판단되는 배경을 제거했다.
- high-level에서는 feature map이 마스크와 곱해져 풍선 픽셀을 정제한다.
2. Attention Module
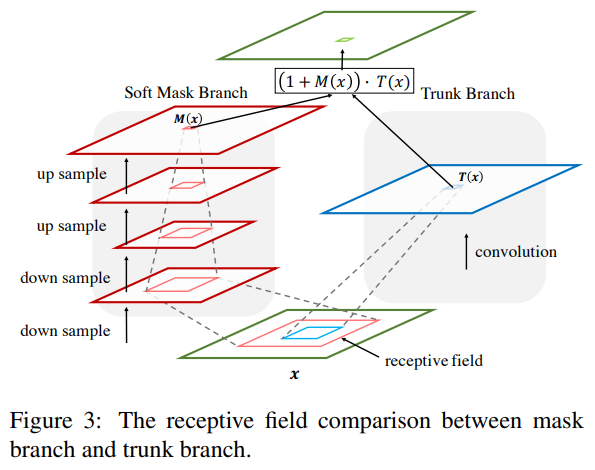
- Attention Module은 soft mask branch와 trunk branch로 두 branch로 나뉘어진다.
- 아래 이미지처럼 Image가 들어오게되면 동일한 image를 각각 soft mask branch, trunk branch 두 방향으로 보낸다. 위가 trunk branch, 아래가 soft mask branch이다.

2.1 Trunk branch
- Attention 연산에서 Value 부분이라고 보면 된다.
- Trunk branch는 Attention module 안에서 입력값으로부터 특징을 추출하며(feature extraction), T(x)로 표현된다.
- Trunk branch는 pre-activation resnet이나 resnext 같은 최신 모듈 구조를 사용하여 모듈로 특징을 추출한다. 출력값으로 T(x)를 출력한다.
- 실제 연산은 image가 들어오면 residual unit을 두번 거치게 된다.
2.2 Soft Mask Branch
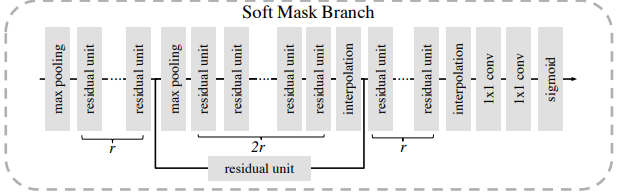
- Soft Mask Branch는 Bottom-up top-down structure를 통해 입력값을 최소 해상도까지 down-sample하고 up-sample로 입력값 크기까지 해상도를 키운다.
- down-sample로 가장 중요한 픽셀을 추출하고, up-sample로 원래 입력값에서 가장 중요한 픽셀의 위치를 파악하여 마스크를 생성한다.
- down-sample은 max-pooling을 사용하고, up-sample은 선형 보간법(linear interpolation)을 사용한다. 그리고 softmax를 거쳐서 0~1 범위의 Mask를 생성하고, 이는 M(x)로 표기한다. ⇒ 이 과정을 거치면 입력값에서 중요한 특징만 살아남게 된다.
- max-pooling으로 가장 큰 값을 이용해서 피쳐맵을 생성하면 작은 값들은 사라지고 상대적으로 영향이 적은 픽셀들이 제거되기 때문이다.
- Mask는 trunk branch 출력값에 곱해져 trunk branch 출력값을 정제하는 역할을 한다.
- 논문에서는 feature selector라는 표현을 쓴다. 그리고 trunk 출력값에서 중요한 특징을 확대할 뿐만 아니라, 노이즈를 제거하는 효과도 있다.
최종적인 attention 결과는 다음과 같다.

- i는 spatial position, c는 Channel의 index를 의미한다.
- 위 식에서 M은 soft mask branch 출력값(0~1 범위), T는 trunk branch 출력값, H는 attention module 출력값을 의미한다.
- 하지만 위 naive attention learning은 layer가 깊어질수록 성능이 떨어질 수 있다. 특히, soft mask branch에서 생성한 마스크는 [0, 1] 범위를 갖기 때문에 0에 해당하는 값이 trunk branch 출력값을 0으로 만들기 때문이다.
- 이를 방지하고자 attention residual learning을 적용하였고, 아래 식과 같이 M에서 0에 해당하는 부분이 1이 된다. 따라서 F(x)를 identity mapping하고, M에서 높은 값에 해당하는 F의 값을 더 키운다.
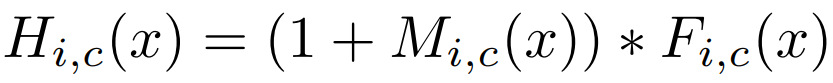
3. Attention Residual Learning
- 3개의 하이퍼파라미터가 p, t, r이 존재한다. 이는 각 파트에서 사용하는 residual unit의 개수를 의미한다.
- 위 논문에서는 p, t, r의 값을 1, 2, 1로 사용한다.

4. Spatial Attention and Channel Attention
- 위 논문에서는 attention type에 대한 실험을 추가로 진행했다.
- 아래 수식 (4)는 일반적인 sigmoid 함수이며, channel / spatial attention이 같이 적용된 mixed attention 형태이다.
- 수식 (5)는 채널별로 L2 normalization이 적용되어 spatial information을 제거한 channel attention이다.
- 수식 (6)은 spatial하게 normalize하여 spatial attention이다.
- i는 spatial position, c는 channel index이다.
- 위 3가지 타입으로 실험했을 때 mixed attentoin이 가장 좋은 성능을 보였다.

5. Residual Attention Network Architecture
- Residual Attention Network 아키텍처는 다음과 같다.

참고:
https://deep-learning-study.tistory.com/536
https://velog.io/@jj770206/Residual-Attention-Network-for-Image-Classification-2017
728x90
반응형
'AI > 딥러닝' 카테고리의 다른 글
| Tensorflow에서 multi GPU 사용 방법 (0) | 2024.11.22 |
|---|---|
| GRU(Gated Recurrent Unit) 정리 (1) | 2024.03.17 |
| LSTM (Long Short Term Memory) 정리 (1) | 2024.03.17 |
| RNN(Recurrent Neural Network) 정리 (0) | 2024.03.17 |
| MLP(Multi-Layer Perceptron)과 CNN(Convolutional Neural Network) 정리 (0) | 2024.03.17 |